
KI und Testen?
Qualitätskriterien für eine neue Welt
von Andrea Kling und Clemens Mucker

Künstliche Intelligenz (KI) und Maschinenlernen revolutionieren unsere Welt: Längst haben personalisierte Kaufempfehlungen, Natural Language Processing und Gesichtserkennung Einzug in unser tägliches Leben gehalten. Und doch ist dies erst der Anfang. In vielen Bereichen bieten die neuen Entwicklungen im Feld der KI vielfältige Möglichkeiten, die erst im vollen Umfang umgesetzt werden müssen. Für Tester und Qualitätssicherer ist das ein weites Betätigungsfeld – doch bei Weitem kein einfaches. Denn mit der steigenden Komplexität und dem zunehmenden Lernvermögen der KI werden neue Testansätze benötigt. Und mit zunehmender Abhängigkeit des Menschen von den lernenden Systemen steigt auch die Verantwortung – nicht zuletzt die des Tests.
Künstliche Intelligenz ist ein weites und unübersichtliches Feld. Es beginnt bereits mit der inflationären Vielfalt von Begriffen. KI, AI, Deep Learning, NLP, Machine Learning, neuronale Netzwerke usw. Daher zuerst eine kleine Begriffsklärung.
Unter Artificial Intelligence (AI) beziehungsweise Künstlicher Intelligenz wird die von Maschinen geleistete Intelligenz verstanden. Dabei wird versucht, die natürliche Intelligenz des Menschen nachzubilden, bei Problemlösungen und Entscheidungsfindungen, aber auch ganz generell im Verhalten. Die Voraussetzung dafür ist, dass die Maschine ihre Umwelt (z. B. in Form von Bildern oder Sprache) „wahrnimmt“ und entsprechende Handlungen vorantreibt, um ein Ziel zu erreichen. Umgangssprachlich wird von KI nur dann gesprochen, wenn kognitive Fertigkeiten wie Lernen oder Problemelösen simuliert werden.
Künstliche Intelligenz wird in der Forschung zusätzlich unterteilt in die schwache und die starke KI. Unter starker KI versteht man, dass die KI den gesamten intellektuellen Fähigkeiten des Menschen in allen Bereichen mindestens ebenbürtig ist. Fähigkeiten wie logisches Denken, Planung und selbstständiges Lernen könnten hierbei Selbsterkenntnis und ein eigenes Bewusstsein ermöglichen. Die KI hätte also den Verstand eines Menschen. Eine schwache KI hingegen ist auf ein konkretes Problem bezogen, bildet also nur einen kleinen Bereich der menschlichen Fähigkeiten nach und übertrifft diese in manchen Fällen bereits. Die Mittel aus Mathematik und Informatik, die hierbei eingesetzt werden, umfassen unter anderem Logik, Regelwerke, Entscheidungsbäume und Maschinenlernen (einschließlich Deep Learning).
Das heute vielversprechendste Teilgebiet der (schwachen) KI ist Machine Learning (ML). Hierbei wird aus Erfahrung Wissen generiert. Das System lernt nicht auswendig, sondern es werden anhand von Trainingsdatensätzen Muster und Strukturen erkannt, und das so erworbene Wissen wird auf neue Datensätze angewendet. Die Theorien und mathematischen Grundlagen hinter Maschinellem Lernen sind weitaus umfassender, als sich hier berücksichtigen lässt.
Auch hier gibt es verschiedene Ansätze. Die aktuell verbreitetsten Ansätze verwenden künstliche neuronale Netze zur Repräsentation des erlernten Wissens. Vereinfacht ausgedrückt, werden dabei neuronale Netze aus dem Gehirn künstlich auf dem Computer simuliert. Deep Learning ist hierbei eine spezielle Form, bei der mehrere (versteckte) Lagen künstlicher Neuronen zwischen einer Ein- und einer Ausgabeschicht verwendet werden. Nach diesem kurzen Überblick werfen wir nun einen genaueren Blick auf das Teilgebiet Machine Learning und insbesondere Deep Learning.
Wie funktioniert Machine Learning?
Stark vereinfacht sind typische Problemstellungen, die sich mittels Maschinellem Lernen (insbesondere mit Deep Learning) lösen lassen:
- Erkennen von Mustern in Datenreihen und Vorhersage der nächsten Werte (z. B. Ableitung von Kaufempfehlungen aus der Einkaufshistorie),
- Clustern von Datenmengen und Zuordnen zu Kategorien (z. B. bei Bild- bzw. Gesichtserkennung),
- Erkennung von Abweichungen vom Normalverhalten (z. B. Erkennung von Störeinflüssen im Betrieb).
Auch „Natural Language Processing“ (NLP) gehört zu den Aufgabenstellungen, für die Deep Learning geeignet ist. Die tatsächlichen Einsatzbereiche des Deep Learning sind schon jetzt breit gefächert. Von Navigationssystemen mit Routenoptimierung, Analyse von Bilddaten für Krankheitsdiagnosen, Risikominimierung bei Finanztransaktionen bis hin zu persönlichen digitalen Assistenten wie Alexa oder Siri reicht die Palette.
Für all diese Anwendungen gilt, dass auf Basis einer Menge von Eingabedaten ein Modell trainiert und konfiguriert wird. Mit diesem Modell wird dann die Wahrscheinlichkeit für verschiedene mögliche Ergebnisse ermittelt. Das wahrscheinliche Ergebnis stimmt folglich nicht in jedem Fall mit dem tatsächlich korrekten Ergebnis überein.
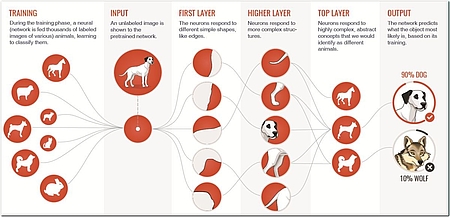
Das Bemerkenswerte an Deep Learning ist, dass dem Computer nicht gesagt wird, woran er die einzelnen Eingabedaten unterscheiden kann. Anhand gelabelter Trainingsdaten entsteht ein Modell, ein künstliches neuronales Netz, das die Erfahrungen repräsentiert und die gewünschten Objekte erkennen kann (siehe Abbildung 1).
Da es sich um Erfahrungen, nicht um eindeutige Kriterien, handelt, bleibt aber immer eine gewisse Fehlerwahrscheinlichkeit – wie auch beim Menschen. Je ähnlicher Objekte sind, desto schwieriger ist die eindeutige Identifizierung. Selbst erfahrenen Biologen fällt es nicht immer leicht, allein am Aussehen zu unterscheiden, ob es sich um einen wolfsähnlichen Hund oder wirklich um einen Wolf handelt. Und genau wie der Mensch kann der Computer durch mehr Daten (und damit mehr „Erfahrung“) die Treffsicherheit sukzessive erhöhen.
Gerade im Internet of Things (IoT) ergeben sich für Deep Learning viele spannende und überraschende Anwendungsmöglichkeiten wie Dialekterkennung für Sprachsystemanwendungen oder Gesichtserkennung für Sicherheitssysteme. Zwei wichtige Dinge sollte man in der Arbeit mit selbstlernenden Systemen nicht vergessen:
- Man arbeitet mit Wahrscheinlichkeiten. Realität und errechnetes Ergebnis stimmen daher nicht überall überein.
- Künstliche neuronale Netze entwickeln ihr Modell aus den Eingabedaten selbst. Es ist also nicht genau nachvollziehbar, nach welchen Regeln das System tatsächlich arbeitet.
Jedes Unternehmen sollte sich fragen, ob der Einsatz von lernender KI für seine Problem- oder Fragestellung notwendig ist. Denn oft lassen sich diese mit einem einfacheren Algorithmus lösen. Es kommt für das Unternehmen meist billiger und ist in bestimmten Fällen auch sicherer, da weniger fehleranfällig. Dass auch mit festen Algorithmen intelligentes Verhalten simuliert werden kann, zeigte bereits in den Sechzigerjahren das Programm ELIZA von Joseph Weizenbaum [Wiki-a].
Qualitätskriterien für Machine Learning
Wie bereits dargestellt, unterscheidet sich die Funktionsweise selbstlernender KI-Systeme deutlich von klassischen regelbasierten Programmen. Das hat auch Auswirkungen auf die Qualität der Ergebnisse und damit auf die Anforderungen, die an solche Systeme gestellt werden sollten. Nachfolgend daher einige wichtige Qualitätskriterien, die man bei der Erstellung, aber auch bei der Planung von KI-Systemen beachten sollte:
Accuracy – Treffgenauigkeit
Wichtigste Eigenschaft eines ML-Algorithmus ist die Treffgenauigkeit der Kategoriezuordnung beziehungsweise der Vorhersage. Die erreichbare Genauigkeit hängt hierbei vom konkreten Problem, vom verwendeten Modell sowie Art und Anzahl der Eingangsdaten ab. Selbstverständlich ist das Ziel, eine höchstmögliche Genauigkeit zu erreichen. Es kann aber sinnvoll sein, eine notwendige Mindestgenauigkeit zu definieren, die durch das System erreicht werden muss, denn es gibt einiges zu beachten.
Wie Rahul Matthan in einem Forschungsbericht des Takshashila Institute feststellte: „Es muss erwähnt werden, dass Algorithmen des maschinellen Lernens und neuronale Netze so konzipiert sind, dass sie ohne menschliches Zutun funktionieren. Folglich werden selbst die erfahrensten Datenwissenschaftler nicht in der Lage sein, vorherzusagen, wie diese Algorithmen die ihnen zur Verfügung gestellten Daten verarbeiten.“ [TDD17]
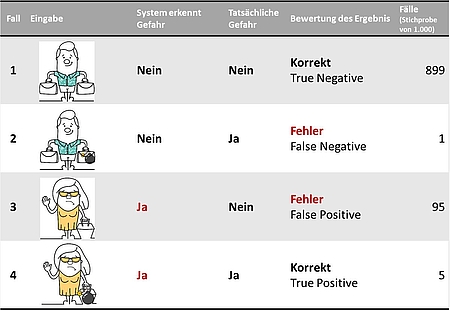
Da wir also nicht wissen, wie das System eingegebene Daten bewerten wird, gilt es, besonders kritisch zu hinterfragen, was das vom System ermittelte Ergebnis tatsächlich bedeutet. Hierzu zeigt Tabelle 1 ein Beispiel für ein mögliches Sicherheitssystem am Flughafen. Die Aufgabe des Systems ist es, gefährliche Personen zu identifizieren.
Da ein lernendes System mit Erfahrungen und Heuristiken und letztendlich mit Wahrscheinlichkeiten arbeitet, wird es unweigerlich auch zu falschen Bewertungen kommen. Im Beispiel erkennt das System Reisende (Fall 1) und Angreifer (Fall 4) korrekt. Es kommt aber auch vor, dass Angreifer nicht erkannt werden (Fall 2) und harmlose Reisende als Angreifer eingestuft werden (Fall 3).
Um entstehende Probleme zu verdeutlichen, wurde die Häufigkeit der verschiedenen Fälle ergänzt. Im Beispiel wird nur ein Angreifer unter 1000 Reisenden nicht erkannt. Das entspricht einer Fehlerrate von 0,1 Prozent und wirkt schon sehr überzeugend. Andererseits werden 95 Reisende fälschlich als Gefahr erkannt. Was für die Reisenden bereits lästig sein mag, hat aber noch eine zusätzliche Auswirkung: Nur 5 von 100 als Gefahr erkannten Personen sind tatsächlich Angreifer, also im Durchschnitt einer von zwanzig manuell kontrollierten. Für die Sicherheitsbeamten kann das Ergebnis wie Aesops Der-Schäfer-und-der-Wolf-Prinzip wirken: Nachdem ohnehin ständig „Wolf“ gerufen wird, wird der Alarm nicht mehr wirklich ernst genommen.
Diese Effekte gilt es, bei der Planung eines KI-Systems entsprechend der Problemstellung zu berücksichtigen. Hier einige Beispiele, die unterschiedliche Ansätze beim Umgang mit False-positive- beziehungsweise False-negative-Bewertungen erfordern:
- Spamfilter: Wichtige Nachrichten fälschlich als Spam zu deklarieren, ist schlimmer, als Spam per Hand auszusortieren.
- Malware/Antivirus: Korrekte Dateien als Malware zu klassifizieren, kann beinahe ebenso problematisch sein wie unentdeckte Malware.
- Biometrik: Soll das System Nutzer sicherheitshalber aussperren oder im Zweifel Zugang gestatten, wenn das Gesicht nicht eindeutig erkennbar ist?
- Medizin: Eine Krebsdiagnose mittels KI könnte viele Fehlalarme („false positive“) auslösen. Das Ergebnis darf jedoch nicht als „hat Krebs“ interpretiert werden, sondern muss als „erhöhter Krebsverdacht, weitere Diagnose erforderlich“ gelten.
Wesentlich ist, dass keinem KI-System blind vertraut wird, ohne dass man sich über die Häufigkeit und Auswirkung von Falschbewertungen Gedanken macht. Für den Test gilt, zu beachten:
- Die Treffgenauigkeit des Systems wird mit der „Lernzeit“ höher. Ein Test sollte daher auf ein Modell zurückgreifen, das bereits vielen produktionsnahen Trainingsdatensätzen ausgesetzt war.
- Je komplexer die Algorithmen werden, desto schwieriger wird es, sie zu testen. Denn – auch wenn es derzeit noch wie Zukunftsmusik klingt – wie kann vorhergesagt werden, was die Maschine lernen wird, zu welchen Schlüssen sie unter Umständen kommt? Ein mathematischer Audit des Algorithmus sollte bereits zu Beginn durchgeführt werden. Anschließend sind Blackbox-Testtechniken gefragt. Kontrolldatensätze und damit durchgeführte Tests sollten sichergestellt sein – auch während des Betriebs. Eventuell sogar ein parallel laufendes Kontrollsystem, dessen Ergebnisse mit der Betriebs-AI verglichen werden.
Robustness – Umgang mit verschiedenen Eingaben
Ein wichtiger Einflussfaktor für die Ergebnisqualität ist die Robustheit gegenüber unterschiedlichen Eingaben. Denn wie bereits der amerikanische AI-Forscher Marvin Minsky feststellte: „Fast jeder Fehler lähmt ein typisches Computerprogramm, während ein Mensch, dessen Gehirn bei einem Versuch versagt hat, einen anderen Weg findet. Wir sind selten auf eine einzige Methode angewiesen. Normalerweise kennen wir verschiedene Wege, um etwas zu tun, sodass, wenn einer von ihnen scheitert, es immer einen anderen gibt.“ [Bock95]
Robustheit gilt es dabei, auf Modell- und auf Datenebene zu berücksichtigen. Auf Modellebene geht es um die Reaktionen der KI auf Unbekanntes. Hier wiederum kann unterteilt werden in Robustheit gegenüber bekanntem Unbekannten (man weiß, dass in einem bestimmten Bereich etwas passieren wird) und gegenüber unbekanntem Unbekannten (man weiß nicht einmal, dass in einem Bereich etwas geschehen wird).
Dieses Unbekannte kann aus den verschiedensten Ursachen heraus entstehen, Beispiele wären unter anderem Anwenderfehler, falsche Modelle, falsch spezifizierte Ziele, Cyberattacken oder unerwartete und daher nicht im Modell vorhandene Phänomene.
Auf der Datenebene gilt es insbesondere, zwei gegensätzliche Probleme zu vermeiden: Bias und Overfitting.
High Bias liegt vor, wenn Eingaben bevorzugt zu einer Ergebniskategorie zugeordnet werden und hierbei zusätzliche Informationen aus den Eingaben unberücksichtigt bleiben. Es beruht also auf fehlerhaften Annahmen im Lernalgorithmus. Bias ist kaum ins Deutsche zu übersetzen, die Bedeutung reicht von Neigung, Tendenz bis hin zu Vorliebe, Vorurteil und Befangenheit. Die Maschine kann nur lernen, was sich aus ihrem Vorwissen heraus erklären lässt.
In diesem Zusammenhang machte in den letzten Jahren „rassistische“ KI von sich reden. Bei einem von einer KI bewerteten Schönheitswettbewerb [Wir16] schaffte es nur eine Person mit dunkler Hautfarbe auf das Siegertreppchen. Aus den zuvor verwendeten Trainingsdatensätzen zu Schönheitsidealen schlussfolgerte das System möglicherweise, dass die Hautfarbe einen starken Einfluss hat. Eine andere Software, die die Rückfallgefahr von Straftätern in den USA [Pro16] berechnen soll, bescheinigt Afroamerikanern fälschlicherweise ein fast doppelt so hohes Rückfallrisiko wie Weißen. Dieser Effekt wird oft durch Underfitting verursacht.
Underfitting tritt auf, wenn ein Modell zu einfach oder zu strikt reguliert ist. Als Konsequenz kann das Modell nicht die Komplexität des Datensatzes abbilden.
Varianz bedeutet, dass der Algorithmus und damit die Maschine überempfindlich auf kleinere, eigentlich unbedeutende Schwankungen der Daten reagiert. Rauschen in den Trainingsdaten kann so zu verzerrten Outputs und Vorhersagen führen. Eine hohe Varianz verursacht eine Überanpassung.
Überanpassung (Overfitting, auch Overtraining) liegt vor, wenn irrelevante oder wenig relevante Eigenschaften in den Entscheidungsprozess einbezogen und übermäßig gewichtet werden. Das Problem dabei: Bei prognostizierten Werten ergibt sich eine hohe Abweichung von den tatsächlichen Werten, wenn nicht alle erwarteten Eigenschaften übereinstimmen.
Ein extremes Beispiel: Wenn die Anzahl der Parameter gleich oder größer als die Anzahl der Beobachtungen ist, kann ein Modell die Trainingsdaten perfekt vorhersagen, indem es die Daten in ihrer Gesamtheit speichert. Es wird jedoch bei der Erstellung von Vorhersagen versagen.
Konkreter: Eine Handschrifterkennung kann ihre Treffgenauigkeit durch Trainingsbeispiele verbessern. Da die Trainingsdaten nur einen Teil der Gesamtmenge möglicher Handschriften enthalten, kann es irgendwann zur Überanpassung kommen: Das Modell lernt nicht nur, die einzelnen Buchstaben zu erkennen, sondern auch die Spezifika der jeweiligen Handschrift. In der Folge verbessert sich zwar die Erkennung der Trainingsbeispiele, die Erkennung anderer, fremder Handschriften verschlechtert sich jedoch.
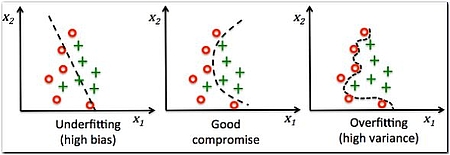
Wie in Abbildung 2 zu sehen ist, werden bei Underfitting zu viele der Daten falsch eingeordnet. Das Bild zum Overfitting rechts sieht auf den ersten Blick fehlerfrei aus, ist aber zu sehr von den Trainingsdaten abhängig. Bei neuen Daten ist daher die Wahrscheinlichkeit höher, dass es eine höhere Fehlerrate produziert als im mittleren Bild. Denn abhängig vom zu lösenden Problem ist die Anforderung an Robustheit gegenüber Rauschen (Noise, irrelevanter Information) und die tatsächliche Verteilung beziehungsweise Bandbreite in den Eingabedaten sehr unterschiedlich. Aufgrund des Verzerrung-Varianz-Dilemmas [Wiki-b] lässt sich aber nicht beides gleichzeitig maximieren. Wissen über die möglichen Eingaben und konkrete Qualitätsziele sind daher unerlässlich.
Für den Test gilt: Sowohl Trainings- als auch Testdatensätze sollten möglichst gleich gewichtet alle realistischen Varianten enthalten, um Bias oder Overfitting zu erkennen und von Anfang an zu vermeiden.
Entdecken lässt sich eine Überanpassung etwa, indem der initiale Trainingsdatensatz in mindestens zwei Datensätze geteilt wird. Der erste – größere – wird zum Lernen verwendet, der zweite als Testdatensatz zur Validierung. Funktioniert das Modell am Trainingsdatensatz viel besser als am Testdatensatz, dann liegt möglicherweise eine Überanpassung vor.
Irrelevante Zusatzinformation („Variance“) lässt sich zudem durch Vorverarbeitung (engl. „Preprocessing“) der Eingabedaten reduzieren. Dementsprechend sollte auch die Vorbearbeitung der Daten in Tests einbezogen werden.
Es lohnt sich, explizit die Reaktion des Systems auf Unbekanntes zu überprüfen: sowohl auf Modell- als auch auf Datenebene.
Lerneffizienz/Anpassung
Wie viele Lernzyklen/Eingabedaten benötigt das System, um akkurate Zuordnungen beziehungsweise Vorhersagen zu erreichen? Auch dies ist ein Qualitätskriterium für Machine Learning. Mit jeder neuen Eingabe, das heißt mit jedem Lernzyklus, korrigiert das System die Gewichtung der Einflussfaktoren. Je nach Implementierung des künstlichen neuronalen Netzwerks und Algorithmus erreicht das System damit schneller oder langsamer eine optimale Genauigkeit.
Welche Anforderungen an die Lerngeschwindigkeit bestehen, hängt oft damit zusammen, wie viele Daten („labeled“ und „unlabeled“) für das Training zur Verfügung stehen. Im Allgemeinen heißt es: Auch langsamer lernende Systeme erreichen eine hohe Genauigkeit, wenn sie nur genügend Trainingsdaten zur Verfügung haben. Für bestimmte häufige Probleme, zum Beispiel Bilderkennung, gibt es sogar schon vortrainierte Modelle.
Auch die Häufigkeit und der Umfang von Änderungen in der Anwendung (z. B. neue zusätzliche Eingabeformate oder zu erkennende Kategorien) können die Anforderungen an die Lerneffizienz beeinflussen.
Performance
Auch bei KI gilt: Hilft sie dem Endanwender, eine gestellte Aufgabe zu erfüllen? Letztendlich spielt auch die Performance des Systems dabei eine Rolle, das heißt, welche Anforderungen an Speicher und Rechenleistung gestellt werden, um Vorverarbeitung, Training, aber auch die eigentliche Problemlösung, in akzeptabler Zeit abzuschließen. Bereits die Vorverarbeitung, also die Vereinheitlichung und Verdichtung der Daten, wie etwa die Normierung von Fotos auf eine einheitliche Auflösung oder Reduktion der Farbtiefe, benötigt unter Umständen einiges an Rechenleistung.
Und der Deep-Learning-Ansatz verlangt ebenfalls massive Rechenpower, damit Objekte erkannt werden oder Sprache übersetzt wird. Die Fortschritte in der KI, die derzeit vor allem auf dem Deep Learning basieren, konnten nur erreicht werden, indem sich die erreichbare Rechenleistung – frei nach Moore´s Law – regelmäßig rasant verdoppelt hat. Dem steht allerdings wieder ein zunehmendes Interesse an der KI und der damit benötigten Rechenleistung gegenüber. Je effizienter die KI dabei die Ressourcen nutzt, desto besser für die weitere Entwicklung, auch damit KI nicht nur das Privileg rechenleistungsstarker Firmen bleibt.
Es bleibt spannend
All das zeigt: Es kommen spannende Zeiten auf uns Tester zu. Qualitätskriterien zu definieren und zu kennen, ist ein wichtiger Schritt. Sie tatsächlich zu überprüfen, wird eine ganz neue Herausforderung.
Literatur
[Bock95] J. Brockman, The Third Culture: Beyond the Scientific Revolution, Simon & Schuster, 1995
[Hong] K. Hong, Artificial Neural Network (ANN) 7 – Overfitting & Regularization, BogoToBogo, siehe: http://www.bogotobogo.com/python/scikit-learn/Artificial-Neural-Network-ANN-7-Overfitting-Regularization.php
[Pro16] J. Larson, S. Mattu, L. Kirchner, J. Angwin, ProPublica, 23.5.2016, How We Analyzed the COMPAS Recidivism Algorithm, siehe: https://www.propublica.org/article/how-we-analyzed-the-compas-recidivism-algorithm
[TDD17] R. Matthan, Beyond Consent: A New Pradigm for Data Protection, Takshashila Discussion Document, 2017-03, siehe: http://takshashila.org.in/wp-content/uploads/2017/07/TDD-Beyond-Consent-Data-Protection-RM-2017-03.pdf
[Wiki-a] https://de.wikipedia.org/wiki/ELIZA
[Wiki-b] https://de.wikipedia.org/wiki/Verzerrung-Varianz-Dilemma
[Wir16] C. Michel, Rassismus? Beim KI-Schönheitswettbewerb gewinnen fast nur Weiße, Wired, 9.9.2016, siehe: https://www.wired.de/collection/life/rassismus-beim-ki-schoenheitswettbewerb-gewinnen-fast-nur-weisse

Andrea Kling
